Offline Reinforcement Learning
Introduction
Offline Reinforcement Learning (RL) is an approach to teaching machines or agents how to make decisions using pre-existing data without interacting with the environment during the learning process. It is an extension of traditional reinforcement learning, where an agent interacts with the environment in real time, receiving feedback (rewards or punishments) based on its actions and updating its behavior accordingly.
Offline RL is particularly useful in situations where data collection through interaction with the environment is either expensive, time-consuming, or dangerous. While this method has enormous potential for improving decision-making in areas such as healthcare, robotics, and autonomous driving, it also presents unique challenges, particularly concerning how well the learned policy will generalize to new, unseen situations when deployed in the real world.
Formal Definition
In reinforcement learning, the learning problem is often modeled as a Markov Decision Process (MDP), represented as:
\[\mathcal{M} = (\mathcal{S}, \mathcal{A}, \mathcal{P}, r, \gamma)\]where:
- \(\mathcal{S}\) is the state space.
- \(\mathcal{A}\) is the action space.
- \(\mathcal{P} (s'\mid s, a)\) is the transition function that defines the probability of moving from state \(s\) to \(s'\) given action \(a\).
- \(r(s, a)\) is the reward function that returns the immediate reward after taking action \(a\) in state \(s\).
- \(\gamma \in [0, 1)\) is the discount factor that governs how much future rewards are valued compared to immediate rewards.
In traditional RL, the goal is to learn a policy \(\pi (a \mid s)\), which specifies the probability of taking action \(a\) in state \(s\), in order to maximize the expected cumulative discounted reward:
\[\mathbb{E}_\pi \left[ \sum_{t=0}^{\infty} \gamma^t r(s_t, a_t) \right]\]However, in Offline RL, the agent is limited to learning from a fixed dataset \(\mathcal{D} = \{(s_i, a_i, r_i, s'_i)\}\), which is typically collected by a behavior policy \(\pi_\beta\) [5]. The behavior policy \(\pi_\beta \\) refers to the strategy that was used to generate the data in the dataset. Its characteristics significantly influence the quality and coverage of the data, as well as the potential for the learned policy to generalize effectively to new situations.
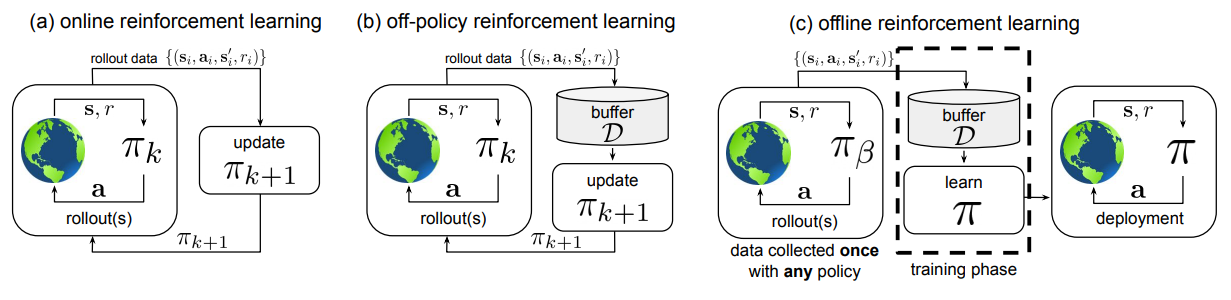
Figure 1: Comparison of different types of reinforcement learning [5].
Figure 1 illustrates the differences between three types of reinforcement learning: online RL, where the agent learns through real-time interaction with the environment; off-policy RL, where the agent utilizes experiences generated by a different policy to improve its own; and offline RL, where the agent learns from a fixed dataset of previously collected experiences without further interaction [5].
The challenge in Offline RL arises from the distributional shift between the state-action pairs in the dataset and those that the learned policy \(\pi\) will encounter. This requires careful policy optimization techniques to ensure that the learned policy remains effective even in the absence of direct exploration.
Overview of Reinforcement Learning and its applications
Offline reinforcement learning (RL) has made significant strides, with advancements in algorithms, theoretical analyses, and empirical applications across various domains.
Several types of algorithms have been used to tackle the challenges of offline RL. Conservative approaches, such as Conservative Q-Learning (CQL) [1] and Bootstrapping Error Accumulation Reduction (BEAR) [14], address distributional shift by penalizing out-of-distribution actions. Model-based methods, like Latent Offline Model-based Policy Optimization (LOMPO) [11], enable the learning of visuomotor policies using offline datasets by constructing an uncertainty-penalized MDP.
Theoretical advancements in offline RL have also gained traction, providing a deeper understanding of its foundations. Recent research has demonstrated that sample-efficient offline RL is achievable under weak assumptions regarding both function classes and data coverage [12]. Furthermore, studies have established a trade-off between representation and coverage conditions, indicating that offline RL can succeed with strong representation or weak coverage, but not necessarily both [13].
Empirical success of offline RL algorithms has been notable across diverse applications. In the realm of Atari games, recent off-policy deep RL algorithms have outperformed fully trained DQN agents on 60 Atari 2600 games when trained solely on fixed datasets [6]. In robotic manipulation, LOMPO has effectively learned visuomotor policies for both simulated and real-world tasks, showcasing the method’s practical applicability [11]. In robot navigation in complex terrains, VAPOR has effetively learnt a navigation policy to navigate through complex terrains with thick vegetation [8]. Additionally, novel techniques have been developed to effectively learn control policies from high-dimensional inputs, broadening the scope of offline RL to more complex and realistic scenarios.
Emerging concepts within offline RL continue to expand the field. Research has identified a “survival instinct” in offline RL algorithms [9], which provides robustness even when trained with incorrect reward labels. The introduction of Iterative Offline Reinforcement Learning (IORL) combines learning from evolving datasets with controlled exploration, allowing for the refinement of policies post-deployment [14]. These advancements highlight the rapid progress in offline RL, addressing key challenges and expanding its potential applications in real-world scenarios where online exploration is limited, risky, or costly.
Applications of Offline Reinforcement Learning for Decision-Making in Robotics
Offline RL is particularly well-suited for robotics applications, where real-world experimentation can be costly, time-consuming or potentially damaging to either hardware or the robots surrounding. It allows robots to learn from previously collected datasets, which can include demonstrations from human experts or data from safe exploration strategies.
For example, in robotic manipulation tasks, offline RL can be used to learn complex behaviors from a dataset of human demonstrations. This approach has been successfully applied to tasks such as grasping objects of various shapes and sizes, or assembling intricate structures for new objects that the robot has not seen before. Furthermore, consider the task of teaching a robot to navigate a new environment [8]. We can collect a dataset of demonstrations, where a human expert navigates the environment. The robot can then learn a policy from this dataset, allowing it to generalize to new, unseen environments. This is particularly useful in scenarios where the environment is dynamic or unpredictable, such as a highway with moving objects or a construction site with changing obstacles, where experimenting with online RL will not be feasible.
Variants of Offline Reinforcement Learning
Offline reinforcement learning (RL) has made significant strides, and a variety of algorithms have been developed to address its unique challenges. These algorithms are designed to ensure that the learning process remains robust, even when trained on fixed datasets. By focusing on effective exploration strategies and mitigating issues like distributional shift [5], these algorithms enable machines to generalize well from the data they have, which is particularly important in fields like autonomous driving. In this section, we will discuss four key algorithms that have become foundational in offline RL: Conservative Q-Learning (CQL) [1], Behavior Regularized Actor Critic (BRAC) [2], Model-based Offline Reinforcement Learning (MOReL) [3], and Batch-Constrained Deep Q-Learning (BCQ) [4].
Conservative Q-Learning (CQL) is a widely used offline RL algorithm that tackles the overestimation problem inherent in Q-learning [1]. By modifying the standard Bellman update to include a regularization term, CQL effectively penalizes Q-values for actions that are out-of-distribution. This ensures that the learned policy does not stray too far from the data it has been trained on, which is essential for maintaining safety in applications like autonomous driving. The CQL objective can be expressed as:
\[\min_Q \alpha \mathbb{E}_{s \sim \mathcal{D}}[\log \sum_a \exp(Q(s,a)) - \mathbb{E}_{a \sim \pi_\beta(a|s)}[Q(s,a)]] + \frac{1}{2}\mathbb{E}_{(s,a,r,s') \sim \mathcal{D}}[(Q(s,a) - (r + \gamma \max_{a'} Q(s',a')))^2]\]Behavior Regularized Actor Critic (BRAC) is another prominent approach that aims to ensure the learned policy remains close to the behavior policy that generated the dataset [2]. By incorporating a regularization term in its optimization objective, BRAC maintains a balance between learning from the data and adhering to the behavior policy, which is crucial for applications requiring safety, like autonomous vehicles. The BRAC optimization can be described as:
\[\max_\pi \mathbb{E}_{s \sim \mathcal{D}, a \sim \pi}[Q(s,a)] - \alpha D_{KL}(\pi(\cdot|s; \theta) || \pi_{\beta}(\cdot|s))\]where \(\mathcal{D}\) represents a divergence measure, such as KL divergence, between the learned policy and the behavior policy.
Model-based Offline Reinforcement Learning (MOReL) introduces a unique framework that learns a dynamics model from offline data to optimize policies [3]. By employing a pessimistic MDP (P-MDP) that penalizes uncertain states, MOReL effectively addresses uncertainties in the learned model, making it particularly valuable in high-stakes environments like autonomous driving. The P-MDP is defined as:
\[\hat{M}_p = \{S \cup \{\text{HALT}\}, A, \hat{r}_p, \hat{P}_p, \hat{\rho}_0, \gamma\}\]where \(HALT\) is an absorbing state and modified reward and transition functions penalize visits to states with high uncertainty.
Batch-Constrained Deep Q-Learning (BCQ) mitigates the extrapolation error inherent in offline RL by constraining action selection based on a generative model of the behavior policy[4]. This ensures that the selected actions are closely aligned with those seen in the training data, reducing the risk of deploying unsafe policies in critical applications like navigation. The action selection process can be described as:
\[a = argmax_{a_i + \xi\Phi(s,a_i,\Phi_i)} Q(s, a_i + \xi\Phi(s,a_i,\Phi_i))\]where \((a_i)\) represents sampled actions from the learned generative model.
By leveraging these algorithms, offline RL is poised to enhance decision-making in robotics and autonomous systems, allowing them to learn from past experiences while minimizing risks associated with real-time exploration.
Challenges and Open Research Directions
Offline Reinforcement Learning has made significant strides, but several challenges and open research directions remain. One primary issue is the distributional shift problem, where the learned policy may significantly deviate from the behavior policy used to collect the dataset. This deviation can lead to overestimation of Q-values for out-of-distribution actions, resulting in poor performance upon deployment. Developing robust methods to address this distributional shift is an active research area [5].
Another challenge is the trade-off between conservatism and optimality. While conservative approaches help mitigate risks associated with out-of-distribution actions, they can limit the discovery of truly optimal policies. Striking a balance between safety and performance optimization is crucial for practical applications of offline RL. Additionally, long-horizon decision-making presents difficulties due to compounding errors in value estimation, leading to unreliable predictions over extended periods [1,5].
The quality and diversity of datasets also pose significant challenges, as the performance of learned policies heavily depends on the offline dataset’s coverage. Research is needed to develop methods that effectively learn from diverse, multi-modal datasets, especially those collected from various sources. Furthermore, combining offline learning with limited online fine-tuning to enhance policy performance while maintaining safety is another important direction for future investigation [5].
Lastly, the interpretability and explainability of offline RL models remain critical, particularly in high-stakes applications like healthcare and autonomous driving. Developing methods that not only perform well but also provide insights into their decision-making processes is essential for building trust and fostering the wider adoption of offline RL techniques. Addressing these challenges is key to unlocking the full potential of offline RL for real-world applications [7].
References
-
Kumar, A., Zhou, A., Tucker, G., & Levine, S. (2020). Conservative Q-Learning for Offline Reinforcement Learning. Advances in Neural Information Processing Systems, 33.
-
Wu, Y., Tucker, G., & Nachum, O. (2019). Behavior Regularized Offline Reinforcement Learning. arXiv preprint arXiv:1911.11361.
-
Kidambi, R., Rajeswaran, A., Netrapalli, P., & Joachims, T. (2020). Morel: Model-based offline reinforcement learning. Advances in neural information processing systems, 33, 21810-21823.
-
Fujimoto, S., Meger, D., & Precup, D. (2019, May). Off-policy deep reinforcement learning without exploration. In International conference on machine learning
-
Levine, S., Kumar, A., Tucker, G., & Fu, J. (2020). Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems. arXiv preprint arXiv:2005.01643.
-
Agarwal, R., Schuurmans, D., & Norouzi, M. (2020, November). An optimistic perspective on offline reinforcement learning. In International conference on machine learning (pp. 104-114). PMLR.
-
Li, J., Tang, C., Tomizuka, M., & Zhan, W. (2022, January). Dealing with the unknown: Pessimistic offline reinforcement learning. In Conference on Robot Learning (pp. 1455-1464). PMLR.
-
Weerakoon, K., Sathyamoorthy, A. J., Elnoor, M., & Manocha, D. (2023). Vapor: Holonomic legged robot navigation in outdoor vegetation using offline reinforcement learning. arXiv preprint arXiv:2309.07832.
-
Li, A., Misra, D., Kolobov, A., & Cheng, C. A. (2024). Survival instinct in offline reinforcement learning. Advances in neural information processing systems, 36.
-
Kumar, A., Fu, J., Soh, M., Tucker, G., & Levine, S. (2019). Stabilizing off-policy q-learning via bootstrapping error reduction. Advances in neural information processing systems, 32.
-
Rafailov, R., Yu, T., Rajeswaran, A., & Finn, C. (2021, May). Offline reinforcement learning from images with latent space models. In Learning for dynamics and control (pp. 1154-1168). PMLR.
-
Zhan, W., Huang, B., Huang, A., Jiang, N., & Lee, J. (2022, June). Offline reinforcement learning with realizability and single-policy concentrability. In Conference on Learning Theory (pp. 2730-2775). PMLR.
-
Xie, T., Ma, Y., & Wang, Y. X. (2019). Towards optimal off-policy evaluation for reinforcement learning with marginalized importance sampling. Advances in neural information processing systems, 32.
-
Zhang, L., Tedesco, L., Rajak, P., Zemmouri, Y., & Brunzell, H. (2023). Active learning for iterative offline reinforcement learning.